
Torulf Jernström is CEO of Finnish developer Tribeflame.
His blog is Pocket Philosopher.
A/B tests are nice and all, but we need to go to the next step.
This is David. He's a nice Columbian guy that somehow lost his way and ended up in Finland.
He designs games for us, looks at data and tunes the games based on this.
Here's a sketch of how it works:
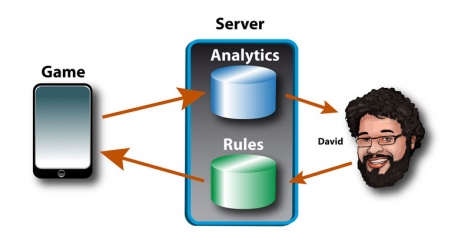
What happens here?
First of all, the player plays the game. Each game session is reported back to our servers.
Don't worry, it's all anonymous. as in player #485712454 failed at level #57, or player #20495 succeeded at level #127.
Finding balance
What we use this data for is basically making the game better.
We can see which levels are too hard or too easy. If a level is too hard, people will obviously get stuck, and then quit the game. If it is too easy, people get bored, and also quit the game.
If the game is balanced just right, people feel challenged and then feel good about themselves and the game when they pass the challenge.
It is reasonable the machine learning algorithm will learn the same rules that the game dev community have figured out. But that is by no means certain.
To achieve the balance, David will look at the data on how players progressed in our game. He will then adjust the difficulty of the game by tweaking level data and various variables.
Psychological edge
The second part of the server is where the rules of the game are kept. Here sits all level data as well as some globally configurable rules.
At every startup, the game client will download a new set of rules and levels from this server.
David will simply put his new configuration on this server, wait for players to play this new, tweaked version, and look at the analytics data again.
There is some lore in the game development community on how to build an optimal challenge curve. Please note that what follows are the "best practices" that are not exactly "scientifically proven" (I know, that's an oxymoron).
The first thought is likely that you make the game increase in difficulty in synch with the players' improving skill. That might work, but we can do better than that.
It is not optimal to always have the player under equal pressure. In fact, that can be exhausting.
So, let's add some waves. Build up to a challenging level, and then when the player finally passes that level, let them rest and feel good about themselves with a few easier levels.
Give them some time to breathe and recover from the challenge. Then you build up to the next challenge.
For F2P games, you likely want to increase the difficulty just a tad more every few waves. These tough levels are where you hope that the player will end up paying you.
Get them 98% of the way to finish a level, and hope that they pay you for a booster that gets them the last 2%.
What we end up with is a curve like this:
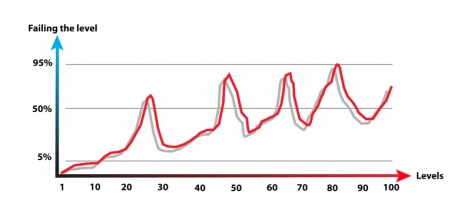
It is not only important to look at how often people win or lose, but also how people lose.
If they always lose in exactly the same way, they will soon get frustrated and quit.
Keep track of how close to winning they are when they lose. And make sure that varies, with a large percent of close calls where the player almost won.
Again, that is when they most likely end up paying. When they play the level for the 20th time, and get 98% of the way to winning.
Now they know that they can use a booster to get over the edge, or they will likely play another 20 times until they are again this close to winning.
What an opportunity! The booster suddenly seems like really good value.
Better by far
So far, so much the wisdom of the game development community. But are these guesses, or facts? And how do they apply to your specific game?
This is where the machine learning algorithm comes in. Markus here is doing his PhD in Machine Learning at the University of Turku, right next to us.
He's looking at what can be done with the data generated by our games. We could try something like this:
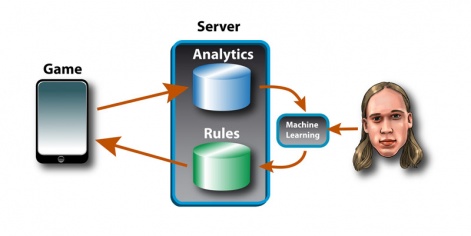
The game reports to our servers, the analytics engine looks at things like fail rates how close to winning they got, who paid for boosters and who stopped or kept playing.
What the machine learning algorithm does is this:
- it has been told to maximise the player long term retention.
- it get's all the player behaviour data
- it modifies the rules, and looks at how the modifications affected the retention
- it automatically learns from this feedback loop what modifications were good and which ones were bad
It is quite reasonable that the machine learning algorithm will learn the same rules that the game development community have figured out.
But that is by no means certain. We might have had it all wrong the whole time since no one has really run a robust enough experiment.
Admittedly, it's still early days for us in trying this out.
I'll let you know if it works once we get that far.


















